Rule Discovery
Multi-agent simulation where autonomous agents discover hidden rules governing a simulated world through experimentation and peer-to-peer communication.
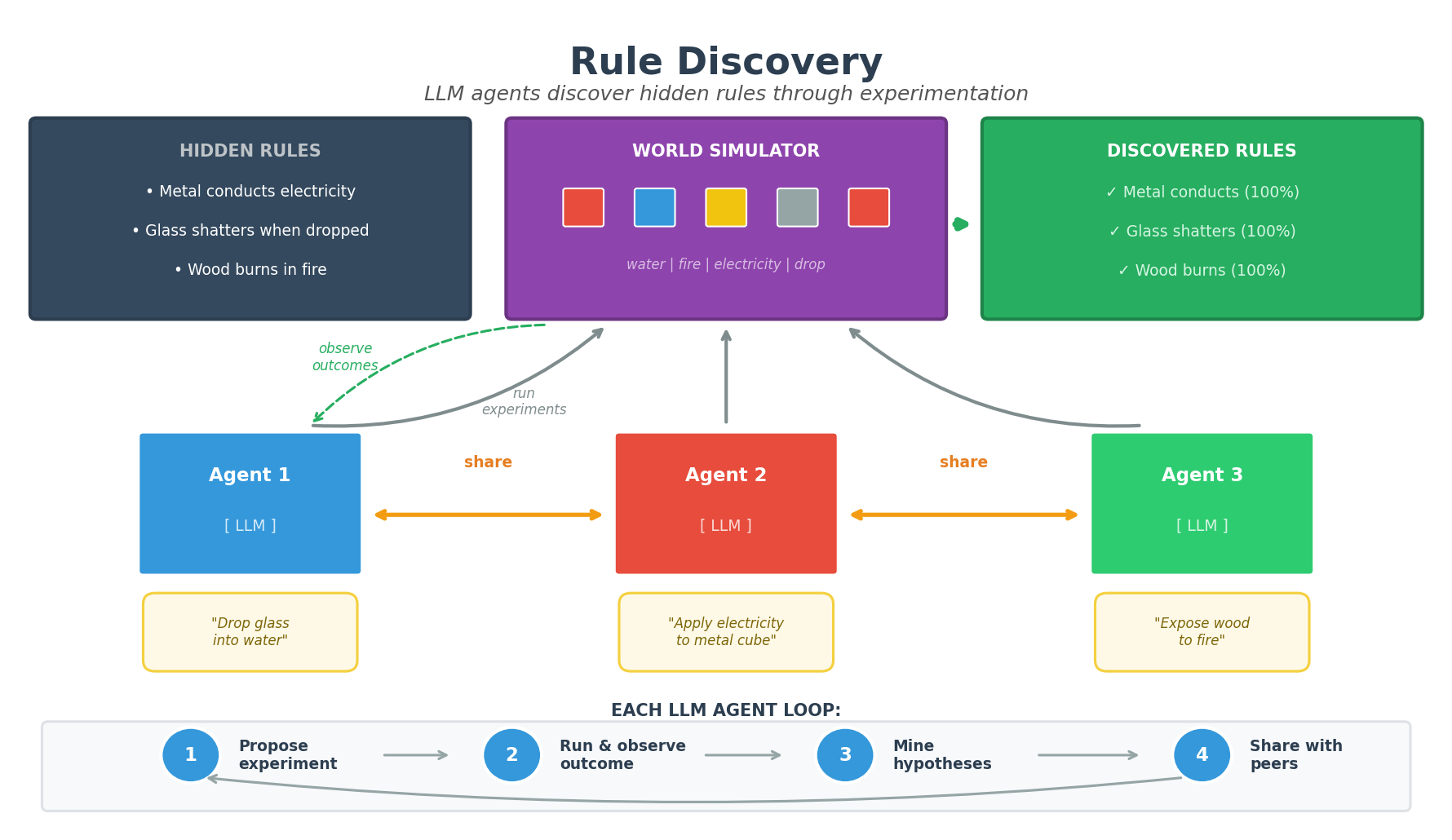
Overview
This project demonstrates automated scientific discovery: multiple AI agents independently run experiments, observe outcomes, identify patterns, and share findings with each other. The goal is to discover the hidden rules that govern how objects behave in a simulated world.
Key concepts:
- Hidden Rules: The world has secret rules (e.g., “metal conducts electricity”) that agents must discover
- Experimentation: Agents propose and run experiments to observe outcomes
- Pattern Mining: Agents use statistical correlation to identify rules from observations
- Communication: Agents share observations with peers, accelerating collective discovery
The Problem
A simulated world contains objects with properties and hidden rules that determine experimental outcomes.
Objects have four properties:
- Color: red, blue, green, yellow
- Size: small, medium, large
- Material: metal, wood, glass, rubber
- Shape: sphere, cube, pyramid, cylinder
Available experiments:
- Drop into water / Drop onto floor
- Apply electricity
- Expose to fire
- Throw at wall
- Place in sunlight
- Put in freezer
Example hidden rules (unknown to agents):
- Metal objects conduct electricity
- Glass objects shatter when dropped
- Rubber objects bounce when thrown
- Wood objects burn when exposed to fire
Example experiment and outcome:
Experiment: "Drop the small red glass sphere into water"
Result: "The small red glass sphere shatters into pieces"
How It Works
Agent Architecture
Each agent runs an asynchronous loop combining LLM reasoning with statistical pattern mining:
┌─────────────────────────────────────────────────────────────────┐
│ 1. PROPOSE EXPERIMENT (LLM) │
│ LLM suggests what to try next, encouraged to explore │
│ diverse material/experiment combinations │
│ → "Apply electricity to the small blue metal cube" │
├─────────────────────────────────────────────────────────────────┤
│ 2. RUN EXPERIMENT (World Simulator) │
│ World applies hidden rules and returns outcome │
│ → "The small blue metal cube conducts electricity" │
├─────────────────────────────────────────────────────────────────┤
│ 3. PARSE & RECORD (Structured Mining) │
│ Extract: material=metal, experiment=electricity, │
│ outcome=conducts │
│ Track correlation: metal+electricity → conducts (count: 5) │
├─────────────────────────────────────────────────────────────────┤
│ 4. GENERATE HYPOTHESES (Statistical) │
│ Find patterns with high evidence and confidence │
│ → "Metal objects conducts when electricity" (100%, n=5) │
├─────────────────────────────────────────────────────────────────┤
│ 5. SHARE WITH PEERS (Probabilistic) │
│ Send structured observations to random peer │
│ Peer merges observations into their own dataset │
└─────────────────────────────────────────────────────────────────┘
Hypothesis Mining
Instead of asking the LLM to formulate hypotheses (which can be unreliable), we use statistical pattern mining:
- Parse observations into structured form:
(material, experiment_type, outcome) - Count correlations: How often does
glass + drop → shatter? - Calculate confidence:
shatter_count / total_glass_drop_experiments - Generate rules: If confidence > 60% and evidence count >= 2, create hypothesis
This approach produces clean, accurate hypotheses like:
- Metal objects conducts when electricity (100% confidence, 5 observations)
- Glass objects shatters when dropped (100% confidence, 8 observations)
- Rubber objects bounces when throw (100% confidence, 12 observations)
Communication
Agents share structured observations (not just text) with peers:
- Each message includes recent
(material, experiment, outcome)tuples - Receiving agent merges these into their own dataset
- This accelerates discovery by pooling experimental evidence
Installation
pip install -r requirements.txt
Usage
Quick Start (Mock Mode)
python hidden_rule_discovery.py --agents 4 --steps 30 --difficulty easy
With Real LLM
Anthropic Claude:
export ANTHROPIC_API_KEY=your-key-here
LLM_PROVIDER=anthropic LLM_MODEL=claude-3-haiku-20240307 \
python hidden_rule_discovery.py --agents 4 --steps 30
OpenAI:
export OPENAI_API_KEY=your-key-here
LLM_PROVIDER=openai_compatible LLM_BASE_URL=https://api.openai.com/v1 \
LLM_MODEL=gpt-4o-mini python hidden_rule_discovery.py --agents 4 --steps 30
Argonne ALCF / vLLM / Other OpenAI-compatible:
LLM_PROVIDER=openai_compatible \
LLM_BASE_URL=https://your-endpoint/v1 \
LLM_API_KEY=your-key \
LLM_MODEL=meta-llama/Llama-3-70b-instruct \
python hidden_rule_discovery.py --agents 4 --steps 30
Command Line Options
Options:
--provider, -p LLM provider: mock, anthropic, openai_compatible
--model, -m Model name (provider-specific)
--agents, -a Number of agents (default: 4)
--steps, -s Number of simulation steps (default: 50)
--difficulty, -d easy | medium | hard (default: medium)
--comm-prob, -c Probability of sharing per step (default: 0.3)
--no-comm Disable communication between agents
--seed Random seed for reproducibility
--log-agents Enable detailed logging of LLM queries and agent actions
Verbose Logging
To see what agents are doing:
python hidden_rule_discovery.py --agents 2 --steps 10 --log-agents 2>logs.txt
Log output includes:
[Agent 0] LLM_QUERY #1: propose_experiment:
...
[Agent 0] LLM_RESPONSE #1: Drop the small red glass sphere into water
[Agent 0] OBSERVATION: glass/drop_water -> shatters
[Agent 0] HYPOTHESES_MINED: 2 rules: ['Glass objects shatters when dropped', ...]
[Agent 0] MSG_SEND #1: to=peer | My top hypotheses: ...
[Agent 1] MSG_RECV #1: from=Agent 0 | ...
[Agent 1] MERGED_OBS: added 3 observations from Agent 0
Difficulty Levels
| Level | Rules | Description |
|---|---|---|
| easy | 3 | Simple material-based rules |
| medium | 5 | Includes color and size interactions |
| hard | 8 | Complex multi-property rules |
Easy (3 rules)
- Metal objects conduct electricity
- Glass objects shatter when dropped
- Rubber objects bounce when thrown
Medium (5 rules)
- Metal objects conduct electricity
- Wood objects burn when exposed to fire
- Blue objects float in water
- Large objects sink in water
- Glass objects crack in the freezer
Hard (8 rules)
- Metal objects conduct electricity
- Metal objects heat up in sunlight
- Wood objects burn in fire
- Wood objects float in water
- Red objects are fireproof
- Small objects fly far when thrown
- Spheres roll when dropped on the floor
- Pyramids tip over on a scale
Sample Output
======================================================================
Hidden Rule Discovery with LLM Agents
======================================================================
LLM Provider: OpenAI-Compatible(gpt-4o-mini)
Difficulty: easy
Number of hidden rules: 3
Number of agents: 4
Communication probability: 0.3
[Hidden rules - for reference only]
- Metal objects conduct electricity
- Glass objects shatter when dropped
- Rubber objects bounce when thrown
--- Step 10 ---
Agent 0: Observations: 10, Messages: sent=3, recv=4
Top hypotheses:
- Metal objects conducts when electricity (100%)
- Glass objects shatters when dropped (100%)
--- Step 30 ---
...
======================================================================
FINAL EVALUATION
======================================================================
DISCOVERED HYPOTHESES:
[TRUE] Metal objects conducts when electricity... (100%) -> matches: Metal objects conduct electricity
[TRUE] Glass objects shatters when dropped... (100%) -> matches: Glass objects shatter when dropped
[TRUE] Rubber objects bounces when throw... (100%) -> matches: Rubber objects bounce when thrown
RULES FOUND (3/3):
+ Metal objects conduct electricity
+ Glass objects shatter when dropped
+ Rubber objects bounce when thrown
RULES MISSED (0):
SCORE: 100/100
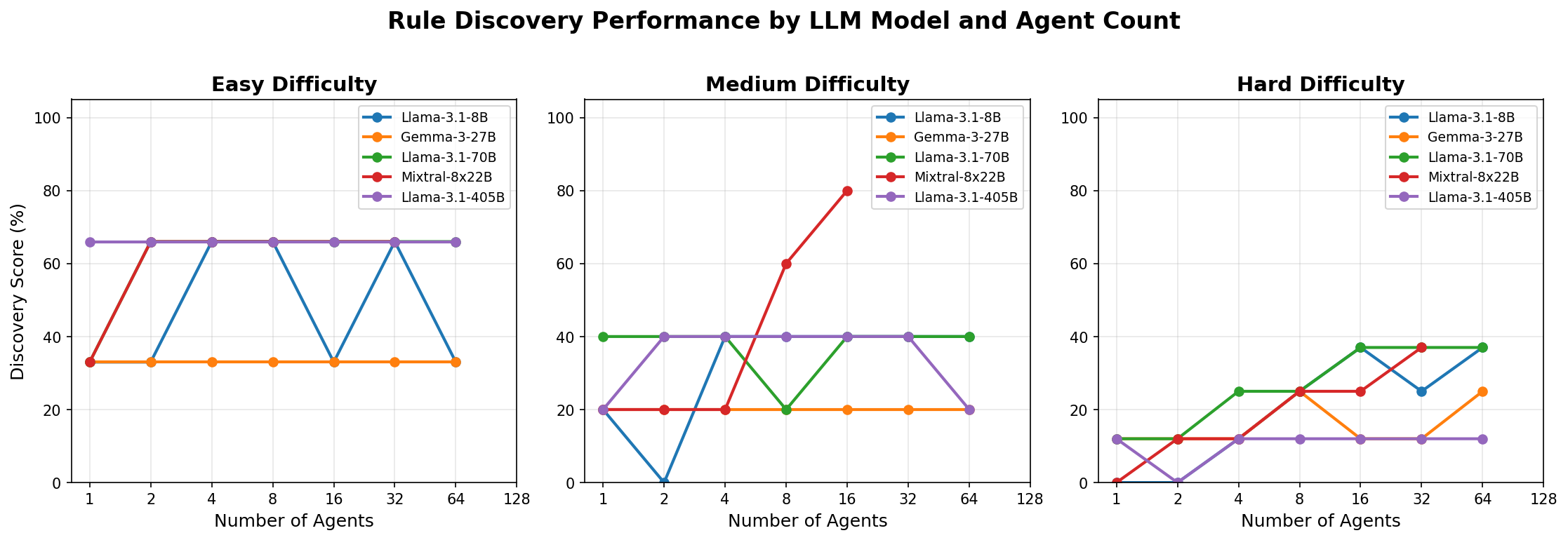
Benchmark Results
We benchmarked multiple LLMs on the Argonne ALCF inference endpoints, varying the number of agents from 1 to 128.
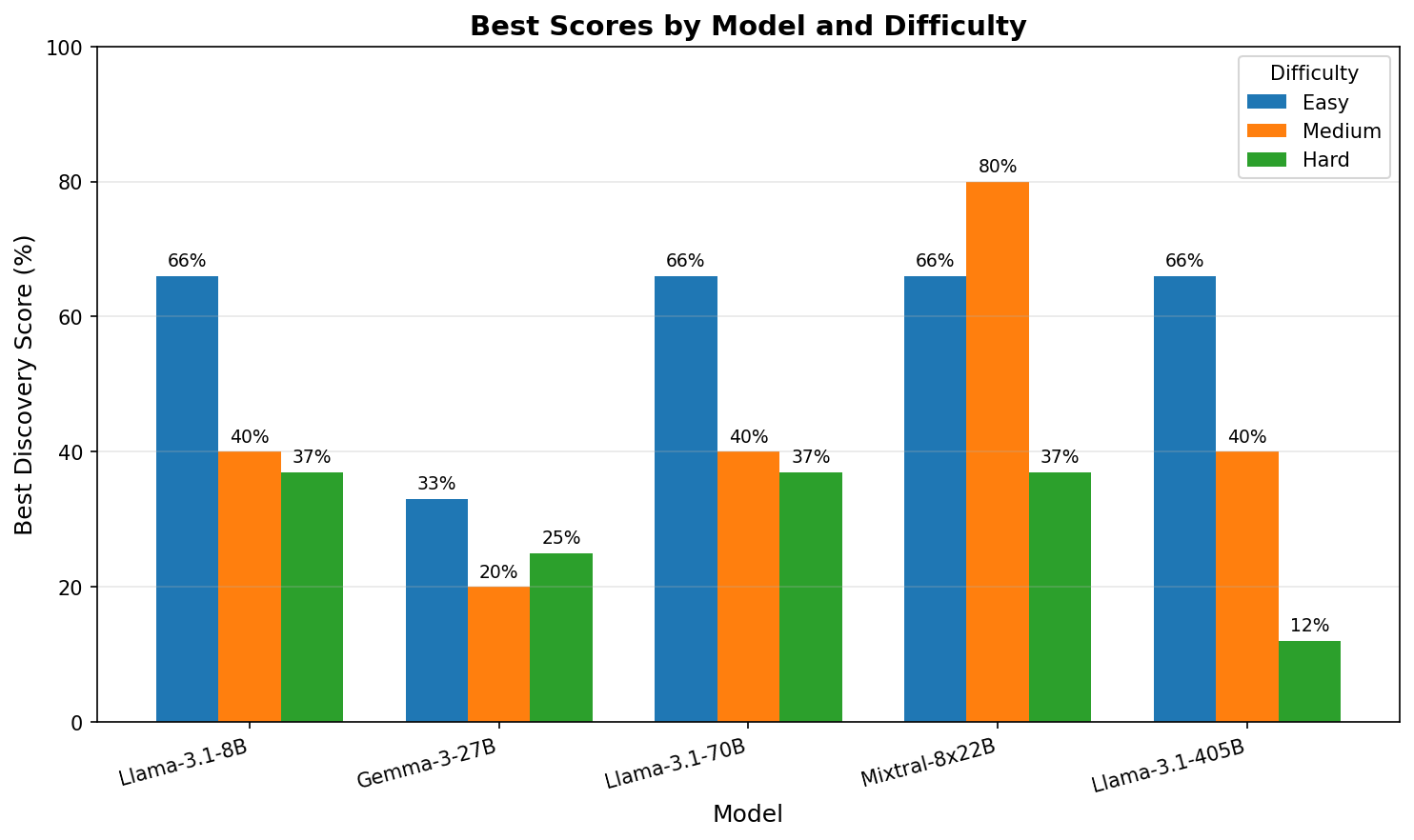
Best Scores by Model
| Model | Easy (3 rules) | Medium (5 rules) | Hard (8 rules) |
|---|---|---|---|
| Mixtral-8x22B | 66% | 80% | 37% |
| Llama-3.1-8B | 66% | 40% | 37% |
| Llama-3.1-70B | 66% | 40% | 37% |
| Llama-3.1-405B | 66% | 40% | 12% |
| Gemma-3-27B | 33% | 20% | 25% |
Performance by Agent Count
Best Scores Comparison
Key Findings
- Mixtral MoE wins on medium difficulty (80%) - best overall performance
- Model size doesn’t correlate with performance - 8B performs as well as 405B for Llama models
- 405B actually worse on hard (12% vs 37%) - possibly over-thinking simple patterns
- Gemma underperforms across all difficulties despite being 27B
- More agents helps on medium - Mixtral peaks at 16 agents with 80%
- Easy plateaus at 66% (2/3 rules) - one rule consistently missed across models
Models Tested
Models tested on Argonne ALCF Sophia cluster:
meta-llama/Meta-Llama-3.1-8B-Instructmeta-llama/Meta-Llama-3.1-70B-Instructmeta-llama/Meta-Llama-3.1-405B-Instructgoogle/gemma-3-27b-itmistralai/Mixtral-8x22B-Instruct-v0.1
Communication & Scaling Experiments
We conducted extensive experiments to understand how communication strategies and agent count affect rule discovery.
Impact of Communication
Communication between agents significantly improves discovery rates. The best strategy is N1_E2: sharing with 1 peer every 2 experiments.
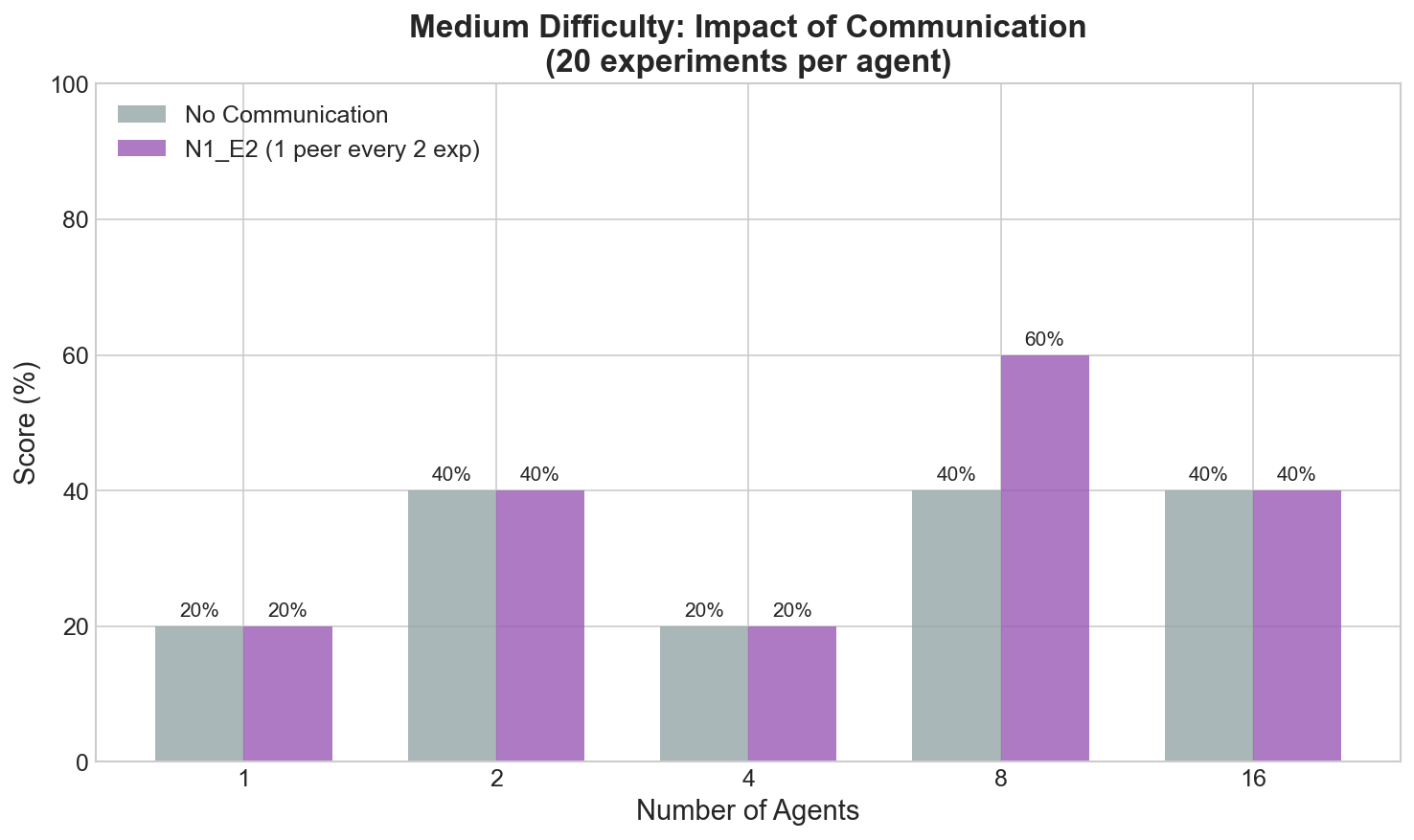
Key finding: With 8 agents, communication improves scores from 40% to 60% on medium difficulty.
Variance Across Seeds
Communication introduces beneficial variance - some runs discover more rules than deterministic no-communication runs.
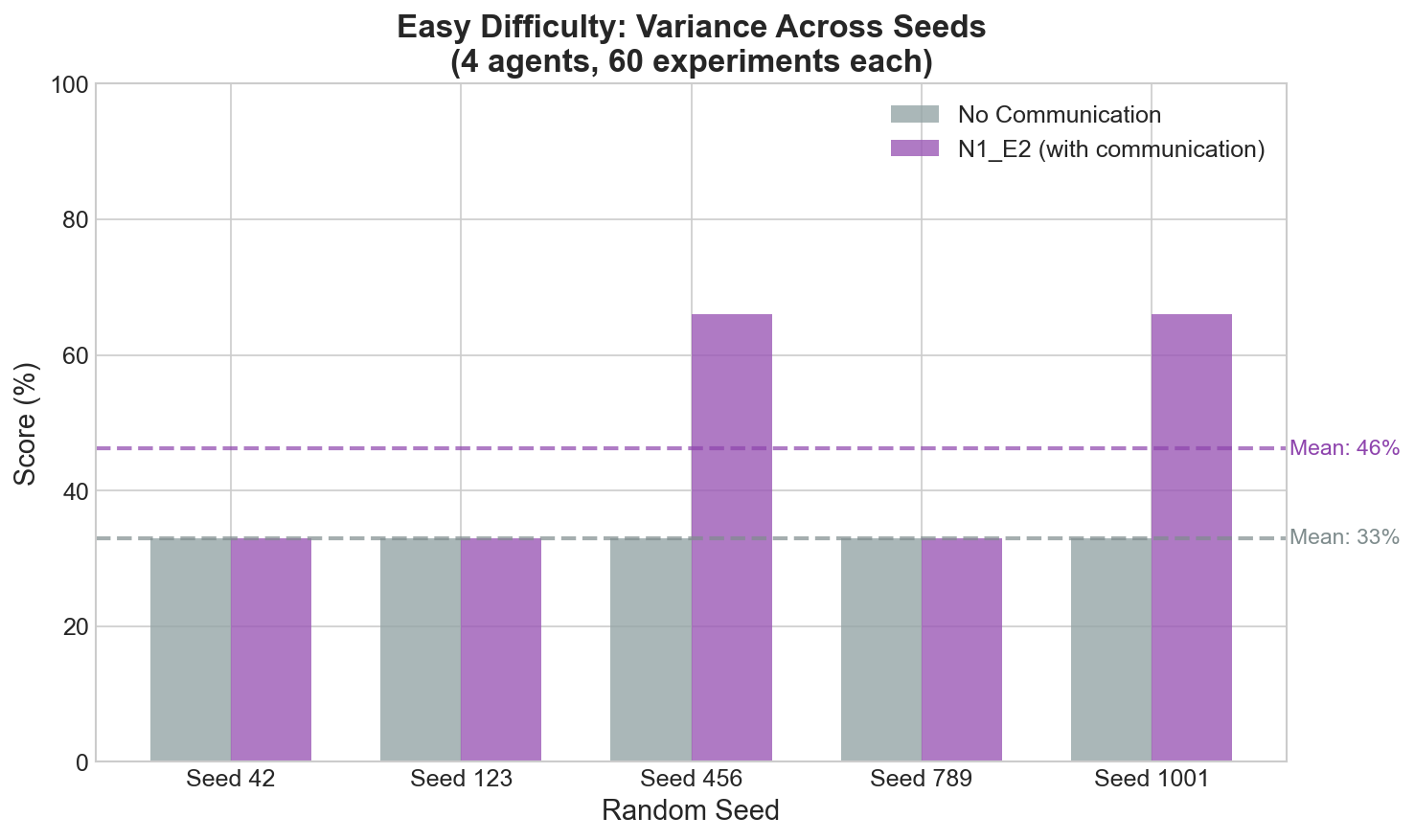
Key finding: No-communication is deterministic (always 33%), while communication produces variance (33-66%) with higher mean (46%).
Hard Difficulty Improvements
We identified and fixed several issues that were limiting Hard difficulty performance.
Before vs After Improvements
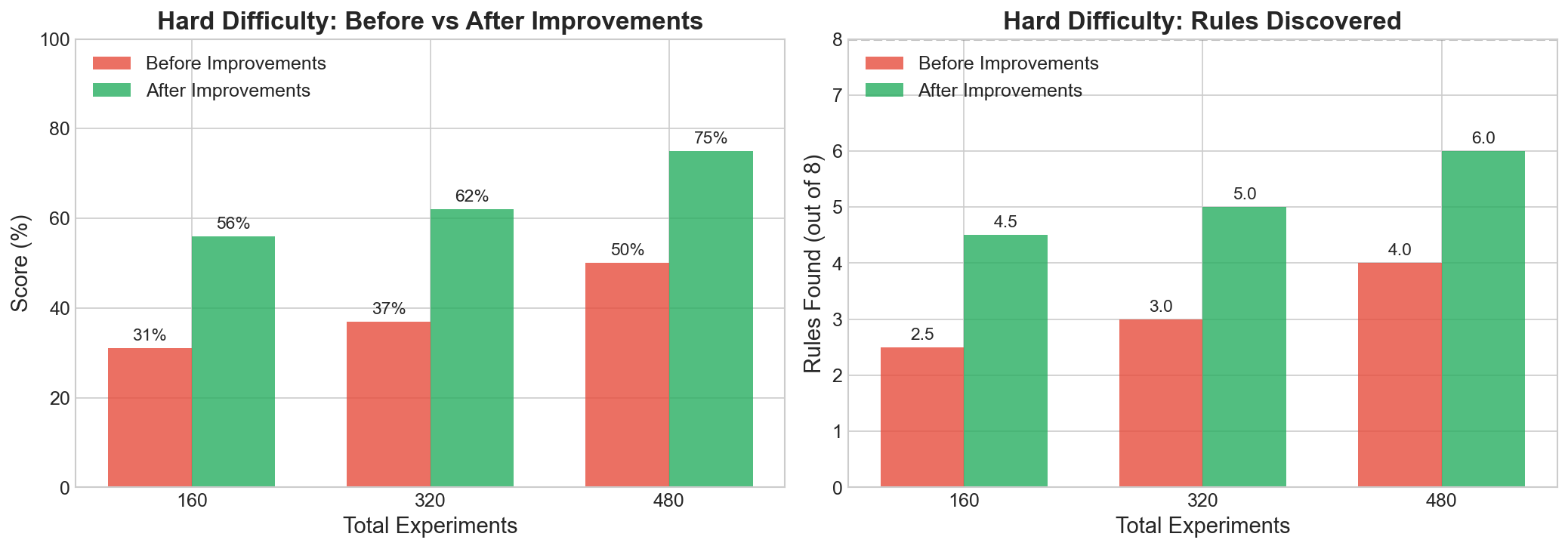
Issues Fixed
-
Missing “scale” action - The “place on a scale” experiment was missing from agent prompts, making “Pyramids tip over on a scale” impossible to discover
-
Forced experiment diversity - Agents now cycle through all 8 experiment types instead of relying on LLM preferences (which biased toward “exciting” experiments like fire/electricity)
-
Lower evidence threshold - Reduced from 2 to 1 observations required, allowing rare property+experiment combinations to be captured
-
Targeted follow-up - 30% chance to re-explore properties that showed interesting outcomes
Scaling with Experiments
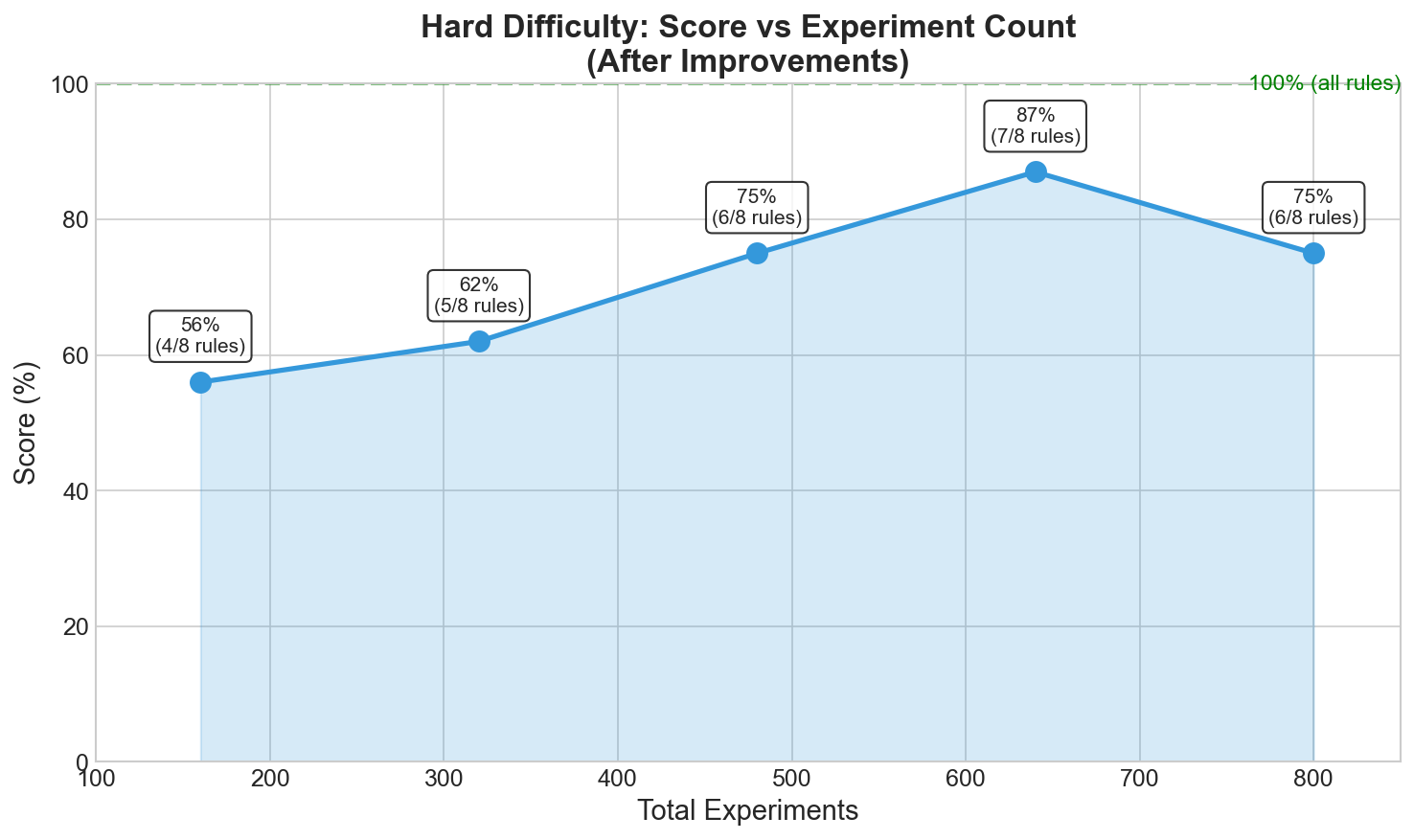
Best result: 87% (7/8 rules) with 640 experiments (8 agents × 80 each)
Summary Dashboard
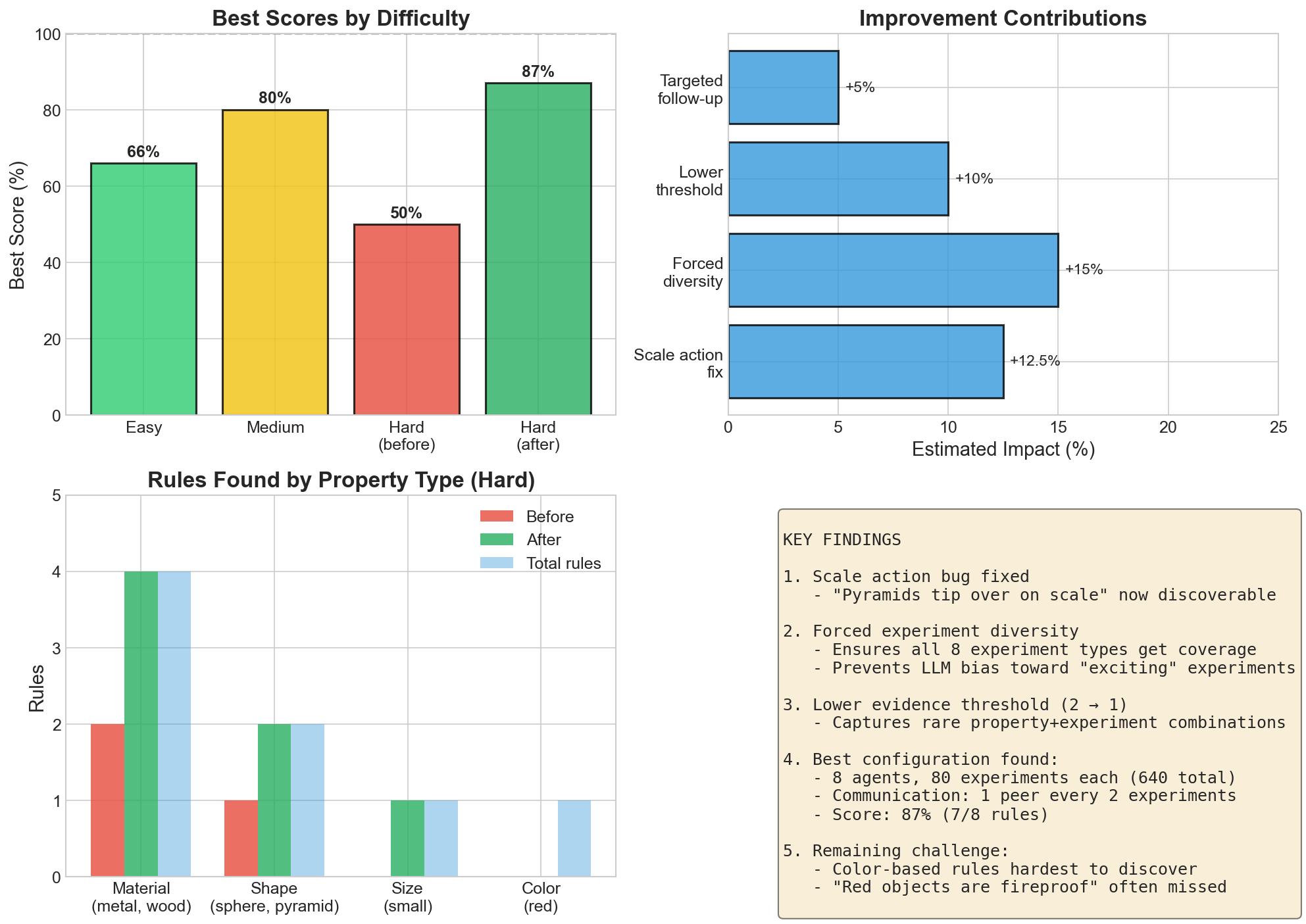
Hard Difficulty Results
| Experiments | Before | After | Improvement |
|---|---|---|---|
| 160 | 31% | 56% | +25% |
| 320 | 37% | 62% | +25% |
| 480 | 50% | 75% | +25% |
| 640 | - | 87% | Best |
Remaining Challenge
The color-based rule “Red objects are fireproof” remains the hardest to discover:
- Competes with “Wood objects burn in fire”
- Red wood objects show immunity, not burning
- Requires sufficient red+fire experiments to establish pattern
Files
| File | Description |
|---|---|
hidden_rule_discovery.py |
Main simulation with agents, world, and evaluation |
llm_providers.py |
LLM provider abstraction (Mock, Anthropic, OpenAI-compatible) |
compare_models.py |
Script to compare different LLMs and agent counts |
compare_comm_strategies.py |
Compare communication strategies (no_comm vs N1_E2, etc.) |
vary_agents.py |
Test scaling with different agent counts |
multi_seed_test.py |
Variance analysis across random seeds |
plot_results.py |
Generate visualization graphs |
results.json |
Cached benchmark results |
figures/ |
Generated graphs and visualizations |
requirements.txt |
Python dependencies |
How Agents Discover Rules
- Exploration: LLM proposes diverse experiments (prompted to try under-tested combinations)
- Observation: World simulator returns deterministic outcomes based on hidden rules
- Pattern Detection: Statistical mining identifies correlations (e.g., “every time I drop glass, it shatters”)
- Hypothesis Formation: High-confidence patterns become hypotheses
- Knowledge Sharing: Agents share structured observations, pooling evidence
- Collective Discovery: Combined observations lead to faster, more complete discovery
Extending
Adding New Rules
Modify create_world() in hidden_rule_discovery.py:
rules = [
Rule(
condition="material == metal", # Property condition
experiment_type="electricity", # Which experiment triggers it
outcome="conducts electricity", # Result text
natural_language="Metal objects conduct electricity" # Human description
),
# Add more rules...
]
Adding New LLM Providers
- Create a class inheriting from
LLMProviderinllm_providers.py - Implement
complete(system: str, user: str, max_tokens: int) -> str - Add to
create_llm_provider()factory
LLM Usage
The system uses an LLM for two tasks:
- Experiment Proposal - The LLM suggests which experiment to run next, encouraged to explore diverse combinations
- Final Evaluation - The LLM compares discovered hypotheses against true rules for scoring
Hypothesis generation uses statistical mining instead of LLM - this produces more reliable, cleaner rules than asking the LLM to reason about patterns.
Dependencies
academy-py- Multi-agent framework for asynchronous agentsanthropic- For Claude modelsopenai- For OpenAI or OpenAI-compatible endpoints (Argonne, vLLM, etc.)